What is protocol overlay? Fundamentals and practical insights
What is protocol overlay? Fundamentals and practical insights
TL;DR:
- Protocol overlays enable flexible, fault-tolerant virtual networks tailored for distributed AI agents.
- Choosing the right overlay type depends on network stability, churn, and performance needs.
- Operational best practices include explicit MTU setup, NAT fallback mechanisms, and continuous observability.
When you’re building distributed AI agent systems, physical network infrastructure rarely gives you the routing flexibility, fault tolerance, or address abstraction you actually need. Engineers often assume that adding more bandwidth or better hardware will solve connectivity problems between agents. It won’t. The real gap is at the logical layer, and that’s exactly where protocol overlays operate. This article breaks down what a protocol overlay is, the types you can choose from, the tradeoffs you’ll face, and the best practices that make agent networks reliable and scalable. If you’re designing peer-to-peer communication for autonomous agents, this is the foundation you need.
Table of Contents
- Defining protocol overlay and why it matters
- Types of protocol overlay: Structured, unstructured, and hierarchical
- Tradeoffs and operational challenges in overlay networks
- Best practices for protocol overlays in AI agent networks
- What most developers overlook with protocol overlays
- Supercharge your AI agent communication with modern protocol overlays
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Overlay essentials | Protocol overlays create customizable, virtual networks on top of physical infrastructure for flexibility and scalability. |
| Types and tradeoffs | Structured, unstructured, and hierarchical overlays each address different performance, resilience, and complexity needs. |
| Implementation pitfalls | Issues like MTU reduction, NAT traversal, and encapsulation overhead require proactive measurement and troubleshooting. |
| Best practices | Prioritize observability, choose UDP-centric protocols, and federate overlays for optimal agent performance across networks. |
Defining protocol overlay and why it matters
A protocol overlay is a virtual network layer built on top of an existing physical network to enable customized topologies, routing, and services for distributed systems. You’re not replacing the underlay. You’re building a programmable layer on top of it that lets you define how nodes discover each other, how data routes between them, and what policies govern those connections.
This distinction matters enormously for AI agent systems. Physical networks are static by design. They route packets based on IP addresses and don’t understand concepts like agent identity, trust, or workload locality. A protocol overlay fixes that by abstracting the physical topology and letting you define a virtual one that fits your application’s logic.
“A protocol overlay enables customized topologies, routing, and services for distributed systems, solving problems that physical infrastructure simply wasn’t designed to handle.”
Here’s a quick breakdown of what overlays bring to distributed AI systems:
| Feature | Physical network | Protocol overlay |
|---|---|---|
| Topology control | Fixed | Programmable |
| Address abstraction | IP only | Virtual/logical IDs |
| Multi-homing support | Limited | Native |
| Policy routing | Minimal | Flexible |
| Fault tolerance | Hardware-dependent | Software-defined |
The AI networking challenges that teams face, like agents behind NAT, cross-cloud reachability, and dynamic peer sets, are all problems that overlays are specifically designed to address. You get fault tolerance through path redundancy, multi-homing so agents can connect over multiple interfaces, and policy routing that lets you prioritize traffic by agent role or data sensitivity.
A common misconception is that overlays are only useful for tunneling, like VPNs. That’s a narrow view. Decentralized communication protocols built on overlay architectures enable service discovery, trust establishment, and dynamic topology changes that go far beyond simple tunneling. For AI engineers, overlays are a system-level innovation platform, not just a connectivity workaround.
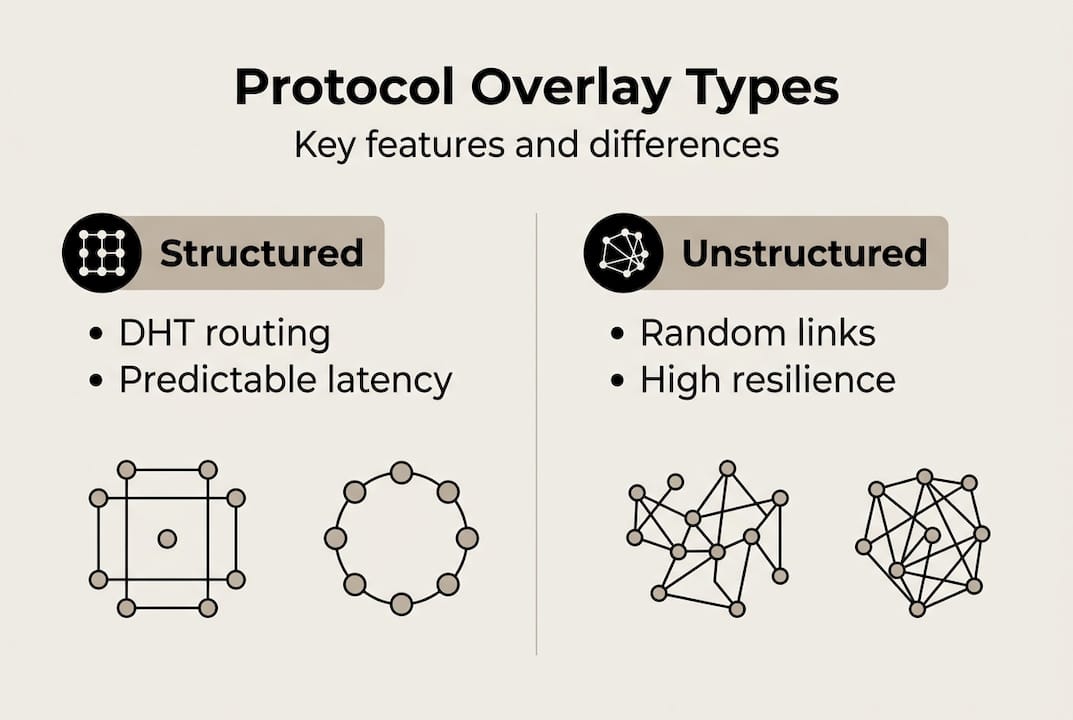
Types of protocol overlay: Structured, unstructured, and hierarchical
Not all overlays are built the same. Choosing the wrong type for your agent network can mean poor lookup performance, excessive bandwidth use, or fragile connectivity under churn. Understanding the three main overlay types helps you make the right call.
Structured overlays use Distributed Hash Tables (DHTs) like Chord or Kademlia. Lookup latency scales at O(log N), meaning even with millions of nodes, you only need a logarithmic number of hops to find a peer. These are ideal when your agents need fast, deterministic peer discovery and you have a relatively stable network topology.
Unstructured overlays use random or gossip-based connectivity. There’s no guaranteed routing path, but the resilience is high. If peers drop in and out frequently, gossip protocols propagate state changes efficiently across the network. The tradeoff is potential inefficiency: searches may flood the network, and latency can be unpredictable.
Hierarchical overlays introduce supernodes, peers with elevated roles that organize and route for clusters of regular peers. This model scales well and balances resource allocation, making it a strong fit for hybrid agent deployments where some nodes have more compute or stable connectivity than others.

Here’s how the three types compare for common distributed AI scenarios:
| Overlay type | Lookup speed | Churn resilience | Best use case |
|---|---|---|---|
| Structured (DHT) | O(log N) | Moderate | Stable agent registries |
| Unstructured (gossip) | Variable | High | Volatile edge environments |
| Hierarchical | Fast via supernodes | High | Hybrid cloud/edge fleets |
For multi-agent system networking, the choice often comes down to three factors:
- Application locality: Do agents need to find peers by content or by ID?
- Expected churn: How often do agents join and leave the network?
- Performance requirements: Is deterministic latency more important than resilience?
If you’re running a stable agent registry in a controlled cloud environment, structured overlays win. If you’re deploying agents at the edge with unpredictable uptime, unstructured or hierarchical overlays give you the resilience you need. You can also review HTTP vs UDP overlays to understand how transport choice interacts with overlay type.
Pro Tip: Don’t lock into one overlay type early. Design your agent communication layer to be transport-agnostic so you can swap or combine overlay strategies as your deployment scales.
Tradeoffs and operational challenges in overlay networks
Overlays solve real problems, but they introduce their own costs. Understanding these tradeoffs before you deploy saves you from painful debugging sessions later.
MTU reduction is one of the first issues you’ll hit. Encapsulation adds headers, shrinking the effective Maximum Transmission Unit. For example, VXLAN reduces MTU from 1500 to around 1450 bytes. If your agents send packets near the original MTU limit, you’ll see fragmentation and packet loss. Always configure MTU explicitly across your overlay stack.
Encapsulation overhead also means higher CPU and bandwidth usage. Every packet gets wrapped, processed, and unwrapped. At scale, this adds up. Empirical overlay performance data shows that these costs vary significantly by protocol and implementation, so benchmark your specific stack rather than relying on theoretical estimates.
Here are the most common operational challenges, ranked by frequency in production deployments:
- MTU misconfiguration causing silent packet loss
- NAT and firewall traversal failures blocking peer connections
- Encapsulation overhead degrading throughput at scale
- Churn from rapidly changing peer sets destabilizing routing tables
- IP address pool overlaps in containerized environments like Docker Swarm
NAT traversal challenges deserve special attention. In libp2p’s DCUtR hole punching implementation, NAT traversal fails roughly 30% of the time without fallback relay mechanisms. That’s a significant failure rate for production agent systems. You need a relay or TURN-equivalent fallback in your design.
Churn, the rapid joining and leaving of peers, is handled differently across overlay types. Gossip and SWIM protocols propagate membership changes efficiently, but they still introduce eventual consistency delays. For agents behind NAT, churn compounds the traversal problem because connection state must be re-established frequently.
On the transport side, UDP overlays outperform HTTP/2 by up to 11x for connection setup time. That gap matters when agents need to establish connections quickly in dynamic environments. TCP-in-TCP tunneling is a pattern to avoid entirely: it causes head-of-line blocking and amplifies latency under any packet loss.
Best practices for protocol overlays in AI agent networks
With the tradeoffs clear, here’s how to build overlay networks that actually hold up in production agent deployments.
Protocol and tool selection should start with WireGuard or libp2p for dynamic, NAT-traversing overlays. Both are well-maintained, have strong community support, and handle the WireGuard/libp2p overlay requirements for P2P agent communication with built-in NAT traversal. WireGuard is especially strong for encrypted tunnels with minimal overhead. libp2p gives you more flexibility for peer discovery and multi-transport support.
Message transport choices directly affect latency and resource use. UDP-based overlays match HTTP latency for messages under 100KB while using less memory and CPU. Prefer UDP for agent-to-agent messaging, but always test for MTU issues and fragmentation in your specific network environment.
Here’s a practical checklist for overlay deployment in agent networks:
- Set MTU explicitly and test with large payloads before going to production
- Implement relay fallbacks for NAT traversal failures
- Use gossip or SWIM for membership management in volatile environments
- Monitor overlay health metrics: connection success rate, latency, and churn rate
- Avoid TCP-in-TCP tunneling under any circumstances
- Test connecting agents across clouds early, not as an afterthought
Observability is non-negotiable. You need real-time visibility into MTU issues, NAT traversal success rates, and peer churn. Without it, you’re debugging blind. Build metrics collection into your overlay layer from day one, not after the first production incident.
For heterogeneous environments where agents run across different cloud providers, regions, or on-premise infrastructure, Synapse-like federation approaches let you bridge overlay networks without forcing a single topology on all participants. This is especially useful for benchmarking UDP overlays across different network segments to find the optimal configuration per region.
Pro Tip: Focus on reachability before raw speed. In NAT-heavy environments, a connection that reliably establishes at 50ms is far more valuable than one that’s theoretically faster but fails 20% of the time.
What most developers overlook with protocol overlays
Most guides cover overlay fundamentals well. What they skip is the operational reality after deployment. The initial setup of a WireGuard or libp2p overlay is straightforward. What breaks teams is everything that comes after: ongoing observability, edge-case NAT failures, and MTU drift as your infrastructure evolves.
The Pilot Protocol overlay challenges documentation is honest about this. Overlays create a new operational surface that requires active management. You can’t set it and forget it.
The real insight is that networking challenges for agents compound over time. A NAT traversal success rate of 85% sounds acceptable until you’re running 10,000 agents and 1,500 of them can’t connect. Measurement isn’t optional. As the benchmark data shows, avoiding TCP-in-TCP and keeping MTU configured correctly are the two highest-leverage actions you can take. Most failures trace back to neglecting these two things.
Supercharge your AI agent communication with modern protocol overlays
If you’re ready to move from theory to implementation, Pilot Protocol gives you a production-ready overlay stack built specifically for AI agent networks. It handles NAT traversal, encrypted tunnels, virtual addressing, and trust establishment out of the box.
You get access to detailed benchmarks, architecture guides, and an agent network infrastructure designed around the real challenges of distributed AI systems. Whether you’re connecting agents across AWS, GCP, and Azure or building autonomous agent fleets that need reliable P2P communication, Pilot Protocol gives you the tools to do it without relying on centralized brokers or complex VPN setups. Start building with a stack that was designed for this problem from the ground up.
Frequently asked questions
What makes protocol overlays essential for AI agent networks?
Protocol overlays provide virtual topologies and NAT traversal that physical networks cannot, enabling distributed AI systems to discover peers, route intelligently, and maintain connections across dynamic environments. Without an overlay, agents are constrained by the rigid addressing and routing of the underlay network.
How do structured and unstructured overlays compare for peer-to-peer communication?
Structured DHT overlays provide low-diameter, deterministic routing ideal for stable agent registries, while unstructured overlays offer higher resilience to peer churn but with variable and sometimes higher latency. Your choice should depend on how stable your peer set is and how critical deterministic lookup times are.
What are common challenges when deploying overlays in agent systems?
The most frequent issues are MTU reduction and NAT traversal failures, along with encapsulation overhead and connection churn that can destabilize routing in large agent fleets. Addressing these requires explicit MTU configuration, relay fallbacks, and real-time observability from the start.
Which protocols are recommended for low-latency AI agent communication?
WireGuard and libp2p overlays are the top recommendations for low-latency, NAT-friendly P2P agent communication, with UDP as the preferred transport for messages under 100KB. These tools combine strong performance with the NAT traversal capabilities that agent networks require.