Trustless protocols that secure decentralized AI systems
Trustless protocols that secure decentralized AI systems

TL;DR:
- Decentralized AI uses cryptography and economic incentives to eliminate the need for human trust.
- The ERC-8004 standard organizes identity, reputation, and validation on-chain for secure agent communication.
- Trustless protocols improve performance, scalability, and security compared to centralized systems.
Decentralized AI can be more secure than centralized systems, but not by adding more layers of human trust. It achieves security by removing the need for trust entirely. Most developers building multi-agent systems assume that decentralization introduces risk because there’s no central authority to enforce rules. That assumption is wrong. Trustless protocols use cryptography, on-chain verification, and economic incentives to enforce every interaction automatically. This guide explains exactly how these mechanisms work, what they look like in real deployments, and how you can apply them to build reliable, scalable, and secure distributed AI agent networks.
Table of Contents
- Why trustless protocols matter for decentralized AI
- Core mechanics: Registries and verifiable inference
- Performance and real-world implementation
- Pitfalls and solutions: Sybil attacks, LLM drift, and validation gaps
- What most developers get wrong about trustless AI protocols
- Connect your agents with trustless P2P: Next steps
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Trustless enables secure decentralization | Trustless protocols replace centralized trust with cryptography and economic incentives, vital for distributed AI. |
| Registries form the security backbone | Identity, reputation, and validation registries underpin agent trust and communication in AI networks. |
| Performance outpaces legacy protocols | Modern trustless frameworks achieve higher throughput and privacy benefits over traditional blockchain solutions. |
| Mitigation of core risks | Sybil attacks and unreliable LLMs are managed by layered validation and progressive trust strategies. |
| Progressive trust outperforms | Combining cryptographic ID, validation, and active challenges yields stronger network reliability than any single method. |
Why trustless protocols matter for decentralized AI
Traditional trust models rely on a central authority, whether a server, a broker, or an administrator, to verify that participants are who they claim to be and that they’re behaving correctly. In distributed AI, that centralized point becomes a bottleneck and a single point of failure. When you have hundreds or thousands of agents operating across clouds, regions, and organizations, you can’t route every verification through one coordinator. The system breaks down under load, and a compromised coordinator exposes every agent in the network.
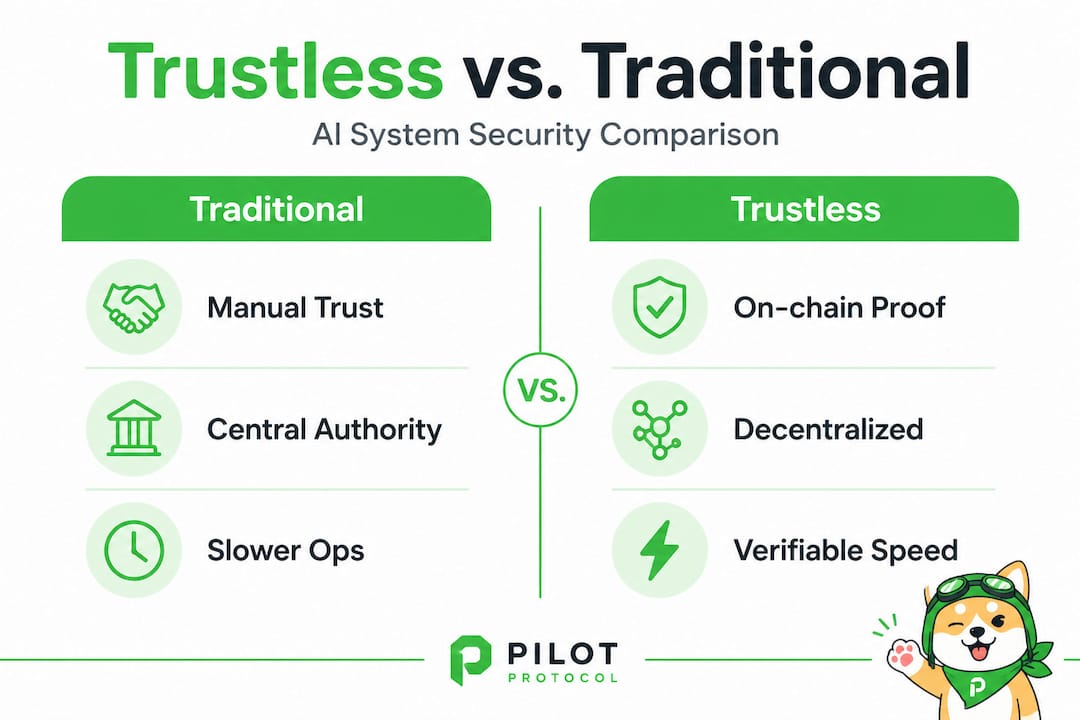
Trustless protocols solve this by shifting verification from social trust (trusting a person or institution) to cryptographic and economic enforcement. No agent accepts a message simply because it came from a known source. Instead, every interaction is authenticated, every claim is verified, and every bad actor faces an economic consequence for misbehaving. Understanding network protocol trust models helps clarify why this shift is so significant for AI workloads.
Trustless does not mean untrusted. It means trust is automated and enforced by code and cryptographic proof, not by human relationships or institutional reputation.
Here’s what trustless protocols replace in a decentralized AI context:
- Social trust: Replaced by cryptographic identity and digital signatures
- Institutional reputation: Replaced by on-chain reputation scores updated by verified interactions
- Manual verification: Replaced by zero-knowledge proofs (zkML) and trusted execution environments (TEE)
- Central enforcement: Replaced by economic incentives and slashing conditions for bad behavior
The ERC-8004 standard formalizes this approach for AI agents, providing on-chain registries for identity, reputation, and validation that any agent in the network can query without trusting any single intermediary.
With this context for why trust is reimagined in decentralization, let’s map the specific mechanisms behind trustless protocols.
Core mechanics: Registries and verifiable inference
The ERC-8004 standard defines three on-chain registries that form the backbone of trustless agent-to-agent (A2A) communication:
- Identity Registry: Uses ERC-721 non-fungible tokens to assign portable, unique agent identities. Each agent holds a cryptographic ID that travels with it across networks and deployments.
- Reputation Registry: Stores on-chain feedback scores ranging from 0 to 100, updated only by authorized parties to prevent spam. Agents with low scores get filtered out automatically before any interaction begins.
- Validation Registry: Manages verification requests, supporting zkML (zero-knowledge machine learning proofs), TEE (trusted execution environments), or stake-secured verification to confirm that an agent’s claimed capabilities are real and functional.
These registries work together to create a full trust pipeline. An agent first proves its identity, then demonstrates its track record through its reputation score, and finally validates its specific capabilities before being allowed to participate in a task. No human needs to approve any step.
| Feature | Traditional centralized model | Trustless protocol model |
|---|---|---|
| Identity verification | Admin-managed credentials | ERC-721 on-chain ID |
| Reputation | Vendor-controlled ratings | On-chain scores, 0-100 |
| Capability validation | Manual review or testing | zkML, TEE, or staking |
| Enforcement | Human or policy-based | Economic incentives, slashing |
| Single point of failure | Yes | No |
Verifiable inference adds another layer to this system. GenLayer’s optimistic challenge-response model assigns a Primary Solver to execute an AI inference task, then allows verifiers to challenge the result using fraud proofs or zero-knowledge proofs. The system assumes at least one honest node exists, and economic incentives penalize (slash) nodes that behave dishonestly. This makes AI inference itself verifiable, not just the communication around it.
Explore decentralized protocol frameworks to understand how these components integrate into full-stack AI deployments. For deeper technical coverage, distributed AI security methods breaks down how verification layers stack in practice.
Pro Tip: When designing your agent registry integration, start with the Validation Registry before scaling. Getting capability verification right early prevents a flood of non-functional agents from degrading your network performance before you have filtering in place.
These mechanisms sound abstract, so let’s clarify how they look in practice and compare their key attributes across real decentralized AI environments.
Performance and real-world implementation
Trustless protocols aren’t just more secure than traditional models. They can also be significantly faster and more efficient, especially when combined with the right data serialization formats.
The DSM framework for blockchain interoperability demonstrates this clearly. Using CBOR (Concise Binary Object Representation) instead of JSON, DSM achieves a 60% reduction in message size, with a compression ratio of 2.5. The result is 250 transactions per second (TPS), outperforming both Cosmos (100-150 TPS) and Polkadot (100-150 TPS) under comparable conditions. For high-frequency agent communication, this difference is significant.
| Framework | Protocol | TPS | Data format | Size efficiency |
|---|---|---|---|---|
| DSM | CBOR | 250 | Binary | 60% reduction |
| Cosmos | JSON | 100-150 | Text | 20-30% |
| Polkadot | JSON | 100-150 | Text | 20-30% |
Privacy is equally important in multi-agent deployments. Research on CAPPR-Wallet and AGENTSNET shows that privacy-preserving protocols can reduce privacy leakage from 85% down to 5%, with key recovery completing in approximately 8 seconds. That’s a dramatic improvement that directly impacts how safely agents can exchange sensitive data, such as model outputs, user inputs, or proprietary training signals.
The AGENTSNET findings also surface a scalability challenge worth noting. Frontier large language models (LLMs) perform well in small agent networks. But as networks grow toward 100 agents, cooperation rates can drop to near zero without additional coordination mechanisms. This is a real constraint you need to plan for.
Key implementation strategies for scaling trustless agent networks:
- Use CBOR serialization for agent messages to maximize throughput and minimize bandwidth costs
- Cap initial network size when deploying new agent types, then scale up with coordination controls in place
- Monitor reputation scores actively rather than treating them as a set-and-forget configuration
- Layer privacy-preserving protocols like CAPPR-Wallet from day one, not as an afterthought
- Apply scalable AI networking practices to design for growth before you need it
For infrastructure that supports cross-cloud and cross-region deployments, P2P AI networking solutions outlines architectural patterns that align with trustless protocol requirements.
250 TPS throughput using CBOR-based trustless frameworks gives you a practical baseline for sizing your agent network capacity. Plan for headroom above this as your fleet grows.
While performance is clearly a benefit, applying trustless protocols isn’t without challenges. Let’s unpack key risks and strategies to overcome them.
Pitfalls and solutions: Sybil attacks, LLM drift, and validation gaps
Trustless protocols are strong, but not invincible. You need to understand their failure modes to deploy them reliably. The ERC-8004 specification identifies three edge cases that directly threaten network integrity.
Sybil attacks occur when an attacker floods the network with fake agents. These fake agents can vote, submit false reputation feedback, or dilute the signal of legitimate agents. The mitigation is strict on-chain reputation filtering combined with anti-spam authentication controls. No agent should receive elevated privileges without a verifiable reputation history. Familiarize yourself with AI network challenges to build Sybil resistance into your design from the start.
Non-functional capabilities are another common problem. An agent may claim to support a specific task or model type, but actually fail when called upon to execute it. The Validation Registry addresses this by requiring agents to prove their capabilities through zkML, TEE attestation, or staking before those capabilities are advertised to the rest of the network.
LLM hallucinations create what researchers call the trust-unreliability paradox. You can cryptographically verify that an LLM agent produced a specific output, but you cannot cryptographically verify that the output is correct or grounded in reality. This is a fundamental tension in decentralized AI systems. An agent can be fully authenticated and still produce confidently wrong answers.
Here’s a practical defense strategy for each threat:
- Against Sybil attacks: Require minimum reputation scores before granting join access. Use token-gated join conditions tied to staked assets so fake agents face an economic cost.
- Against non-functional agents: Enforce Validation Registry checks as a prerequisite for task assignment, not an optional step.
- Against LLM drift: Implement periodic challenge-response tests where agents are asked to re-verify specific capabilities on a rolling schedule.
- For overall resilience: Follow the invisible agent trust model and apply progressive trust as your default.
Pro Tip: Progressive trust works like a probationary period. New agents start with minimal permissions and earn broader access only after demonstrating reliable behavior through multiple validated interactions. This approach drastically reduces the blast radius when a bad actor enters your network.
Having mapped both the strengths and the risks, it’s time to bring these concepts together with an expert perspective for your decentralized AI deployments.
What most developers get wrong about trustless AI protocols
The biggest mistake we see is treating trustless protocols as a cryptography problem. Developers spend enormous effort selecting the right signing algorithms and encryption schemes, then deploy agent networks with no economic security layer and no active validation. Cryptography alone is not enough. An agent can have a perfectly valid cryptographic identity and still be a bad actor with a high reputation score that was gamed through coordinated fake feedback.
The ERC-8004 guidance for AI developers is explicit on this point: the right approach combines cryptographic IDs, verifiable credentials (VCs), and challenge-response mechanisms into a layered progressive trust model. Each layer compensates for the weaknesses of the others. Cryptographic ID proves who the agent is. VCs prove what it’s authorized to do. Challenges prove it can actually do it right now, under current conditions.
A second failure pattern is passive validation. Many teams configure the Validation Registry once at deployment and never revisit it. Production deployments require active validation: periodic fraud proof submissions, regular re-staking checks, and scheduled capability re-verification. Agents change. Models get updated. An agent that passed validation six months ago may be running a degraded or compromised version today.
The third issue is underestimating the LLM reliability gap. Trustless protocols can enforce communication security and agent identity. They cannot guarantee that an LLM produces accurate outputs. The right response is to scope your trustless guarantees clearly. Guarantee authenticated communication and verified agent identity. Then layer separate quality controls, such as output cross-referencing between multiple independent agents, to address LLM reliability specifically.
Applying secure P2P communication tips alongside a progressive trust architecture gives you the foundation that successful production deployments consistently rely on. Trust is not a single switch you flip. It’s a pipeline you build, monitor, and maintain.
Connect your agents with trustless P2P: Next steps
Trustless protocols give you a clear path to secure, scalable, and verifiable agent communication. But theory only takes you so far. You need infrastructure designed to operationalize these concepts in production.
Pilot Protocol is built specifically for this. It provides trustless P2P for AI agents with virtual addresses, encrypted tunnels, NAT traversal, and mutual trust establishment so your agents can find, verify, and communicate directly without relying on centralized brokers or message servers. Whether you’re running a fleet of autonomous agents across multiple clouds or orchestrating cross-region AI workflows, Pilot Protocol gives you the networking layer that makes trustless communication practical and production-ready. Start building today and deploy your first trustless agent connections with confidence.
Frequently asked questions
How do trustless protocols prevent Sybil attacks in multi-agent AI systems?
Trustless protocols filter fake agents using strict on-chain reputation scores and anti-spam authentication, making Sybil attacks economically costly and technically difficult to execute at scale.
What are the three core registries in ERC-8004 and their functions?
ERC-8004 uses an Identity Registry for portable agent IDs via ERC-721, a Reputation Registry for on-chain feedback scores from 0 to 100, and a Validation Registry for verifying agent capabilities through zkML, TEE, or staking.
How does performance compare between trustless protocol frameworks and traditional blockchain systems?
Trustless frameworks like DSM achieve 250 TPS using CBOR compression, significantly outperforming Cosmos and Polkadot, which typically deliver 100 to 150 TPS using JSON-based messaging.
What is the best practice for establishing agent trust in decentralized networks?
Apply progressive trust by starting agents at minimal privileges and escalating access only after cryptographic verification, successful ERC-8004 validation, and positive on-chain reputation history accumulate over real interactions.
How do trustless protocols address AI LLM reliability issues?
They introduce validation registries and verification challenges to detect and exclude agents with non-functional or consistently unreliable LLM outputs, reducing the impact of the trust-unreliability paradox in decentralized agent networks.