AI Agent Discovery Process on P2P Networks: A Step-by-Step Guide
AI Agent Discovery Process on P2P Networks: A Step-by-Step Guide

TL;DR:
- AI agent discovery involves structured metadata announcement and semantic network queries.
- Decentralized methods like DHT and gossip networks offer greater resilience for large, dynamic agent fleets.
- Rigorous verification, including trust scores and cryptographic signatures, is essential to prevent security breaches.
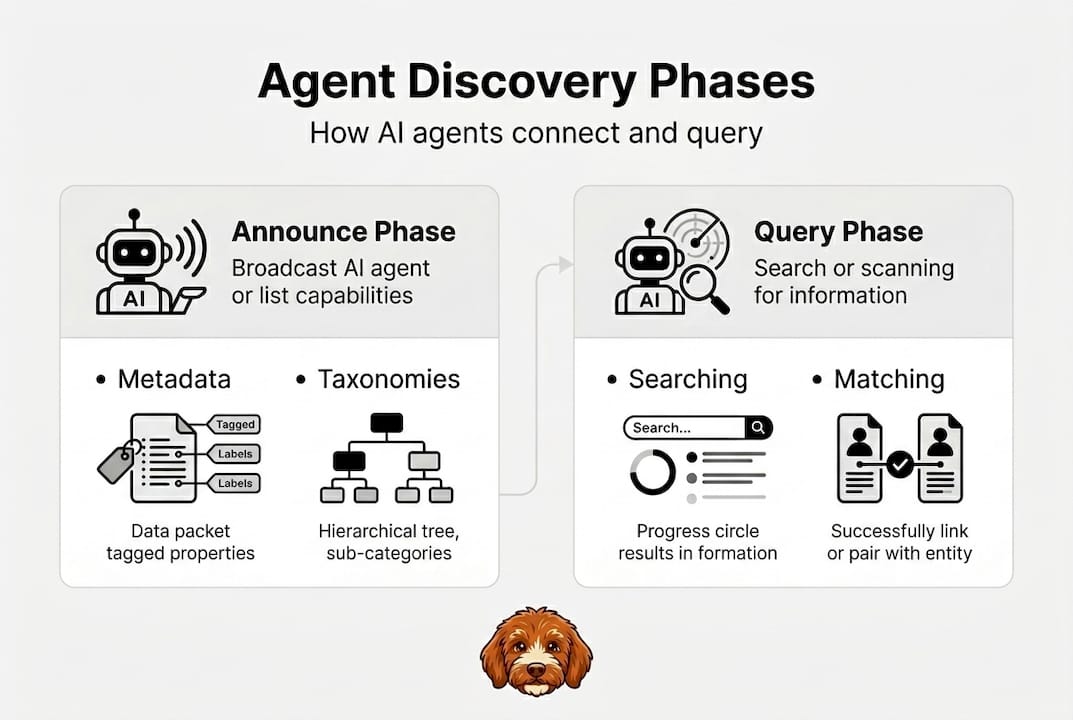
The AI agent discovery process on a peer-to-peer network runs in two phases: agents announce structured, verifiable capability metadata, then other agents query that metadata semantically and verify trust before connecting. Two AI agents need to exchange data securely across a decentralized network. Neither knows where the other is, what it can do, or whether it can be trusted. This is the discovery and trust bottleneck that slows down nearly every serious multi-agent deployment. Solving it is not optional. The way you handle agent discovery directly shapes your network’s security, reliability, and efficiency at scale. This guide walks you through every phase, from preparation to verification, so you can build a robust, trust-enabled peer-to-peer agent network that holds up under real-world conditions.
Table of Contents
- What you need to know before starting
- Step-by-step: Announcing agent capabilities
- Step-by-step: Discovering and querying other agents
- Verifying agents and trust: Benchmarks and best practices
- A fresh perspective: Why most AI agent discovery processes fail (and how to succeed)
- Power your peer-to-peer agent discovery with Pilot Protocol
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Discovery is two-phase | Agents first announce capabilities, then other agents query using structured, semantic methods. |
| Verification boosts trust | Risk-aware multi-factor checks make networks robust, even when faced with malicious agents. |
| Centralized vs decentralized | Centralized registries suit small or transient networks while decentralized models scale and offer resilience. |
| Benchmark-driven design | Using empirical results for coordination and verification ensures tractable, reliable AI agent discovery at scale. |
What you need to know before starting
Before writing a single line of discovery logic, you need a clear picture of how the process works and what tools you’ll rely on. Agent discovery is a structured, two-phase operation. First, agents announce their capabilities using structured metadata. Second, consumers query the network using semantic matching to find the right agents. Understanding both phases separately makes implementation far less error-prone.
The discovery process is two-phase: agents announce capabilities via structured metadata, then consumers query the network via semantic matching, retrieving records from DHT-mapped endpoints. A DHT, or Distributed Hash Table, is a decentralized data structure that maps keys to values across many nodes without a central server. A CID (content identifier) is a content-addressed identifier that uniquely fingerprints a piece of data.
You also need to choose your network model early. Centralized registries like Google A2A broadcast or Prompts Plaza work well for small or ephemeral networks, while decentralized DHT and gossip-based models handle large-scale, dynamic deployments with far more resilience. Choosing the wrong model for your scale is one of the most common early mistakes. Review decentralized protocol models to assess which fits your architecture before you commit.
Tools and standards checklist
| Component | Purpose | Recommended option |
|---|---|---|
| Taxonomy standard | Standardize capability descriptions | OASF |
| Discovery endpoint | Where agents register and query | DHT or decentralized registry |
| Content identifier | Fingerprint metadata records | CID (content-addressed) |
| Schema validator | Catch metadata errors before publish | Open-source OASF validators |
| Gossip protocol | Propagate updates across nodes | libp2p gossipsub |
Key prerequisites before you start:
- A defined taxonomy standard (OASF is the current best option for interoperability)
- Access to a DHT node or decentralized registry endpoint
- A schema validator integrated into your build pipeline
- A clear agent capability inventory (skills, versions, trust metadata)
- Familiarity with agent discovery basics to avoid reinventing solved problems
For semantic taxonomies in practice, the alignment between vocabulary and real capability descriptions is what makes matching reliable.
Pro Tip: Start with widely adopted taxonomies like OASF rather than building custom schemas. Custom schemas fragment the ecosystem and make cross-network discovery far harder to achieve.
Step-by-step: Announcing agent capabilities
Making your agent discoverable is the first concrete action you take. This phase is about publishing a clear, structured, and validated record of what your agent can do so that other agents can find it through semantic queries.
The announcement phase requires agents to publish structured metadata using OASF taxonomies and CIDs into a DHT-accessible registry. This metadata becomes the searchable fingerprint of your agent on the network.
Follow these steps to complete a successful capability announcement:
-
Choose your taxonomy standard. OASF is the recommended choice for current interoperability. It provides standardized skill categories, endpoint schemas, and versioning fields that most discovery engines already support.
-
Build your capability metadata block. Include the following fields at minimum: skill names and categories (mapped to OASF), endpoint URLs, version number, trust score, and a CID that uniquely identifies this metadata record. Missing or malformed fields cause silent discovery failures.
-
Register the record in your DHT or decentralized registry. Use your DHT client library to publish the capability record. For libp2p-based stacks, this means calling the DHT put operation with your CID as the key. Confirm the record propagates to multiple nodes before considering the announcement complete.
-
Validate metadata for both syntax and semantics. Syntax validation checks that your JSON or YAML is well-formed. Semantic validation checks that your skill labels actually map to recognized OASF categories. Both checks are necessary. An agent with syntactically valid but semantically mismatched labels will never appear in relevant query results.
-
Monitor record freshness. DHT records expire. Set up a background process that re-announces capabilities on a defined interval, typically every few hours, to keep your agent visible. Stale records cause intermittent discovery failures that are difficult to debug.
Check out the full announcement process and how it fits within broader agent networking architectures for more context on where this step sits in the larger system design.
Pro Tip: Use open-source schema validators as a pre-commit hook in your CI/CD pipeline. Catching metadata errors before they reach the registry saves hours of debugging intermittent discovery failures later.
Step-by-step: Discovering and querying other agents
Once your agent is announced, you need to know how to find other agents. The querying phase is where your taxonomy investment pays off directly. Precise semantic queries return precise results.

Consumers query via semantic matching on taxonomy keys, retrieving matching agent records from DHT-mapped endpoints. Loose or generic queries return noisy result sets. Tight, taxonomy-aligned queries return relevant candidates with far less post-processing.
Here is a step-by-step walkthrough of the query process:
-
Build a structured query using taxonomy semantic keys. Map your requirements to OASF skill categories. Specify version constraints and endpoint type requirements if relevant. The more precise the query, the smaller and more useful the result set.
-
Send the query to your DHT or gossip endpoint. For DHT-based networks, use a DHT get operation with your constructed key. For gossip-based networks, broadcast the query and collect responses within a defined timeout window.
-
Retrieve and deserialize the result set. Each result is an agent record containing capability metadata, endpoint information, and trust signals. Parse each record and discard any that fail schema validation.
-
Rank and filter candidates. Sort results by trust score, version compatibility, and endpoint reachability. Remove agents that fail liveness checks.
-
Initiate contact with the top candidate. Use the endpoint from the selected agent record to open a direct connection. Refer to the direct agent protocol guide for connection setup details.
Centralized vs decentralized discovery comparison
| Scenario | Best model | Coordination style |
|---|---|---|
| Small, short-lived agent fleet | Centralized registry (A2A) | Explicit messaging |
| Large, dynamic, multi-region fleet | Decentralized DHT/gossip | Implicit or pressure-field |
| Mixed or hybrid environment | Hybrid approach | Explicit + implicit |
One critical distinction worth understanding is explicit vs implicit coordination. Explicit coordination uses direct messaging between agents. Implicit coordination uses shared environmental signals to guide agent behavior without direct communication, which can reduce messaging overhead in high-agent-count scenarios at the cost of directness. See P2P networking examples for implementations of both approaches.
Verifying agents and trust: Benchmarks and best practices
Discovering an agent is not the same as trusting it. Verification is a separate, mandatory step. Skipping it exposes your network to Sybil attacks, where malicious actors flood the network with fake agent identities to disrupt operations or intercept data.
Implement multi-factor verification for every discovered agent:
- Trust score check: Query the agent’s published trust score and cross-reference it with your network’s trust ledger if one exists.
- Signed capability verification: Confirm that the agent’s capability metadata is cryptographically signed and that the signature is valid.
- Previous interaction history: Factor in prior successful or failed interactions when deciding whether to proceed.
- Liveness and endpoint check: Confirm the agent is reachable at its declared endpoint before investing further in the connection.
The empirical case for rigorous verification is strong. Risk-aware verification in P2P networks stays substantially more robust than naive-trust approaches as the Sybil ratio rises across the tested range toward 50%, while no-verify approaches degrade at much lower infiltration rates. Trust verification matters just as much once agents are connected — see encrypted tunnel advantages for peer-to-peer AI networks for how to keep that connection itself secure end to end.
Risk-aware selection kept the network functional across Sybil ratios up to 50% in the paper's sweep, while naive-trust selection degraded far earlier.
Common mistakes to avoid:
- Bypassing verification to reduce latency (the tradeoff is not worth it)
- Relying on static trust metrics that do not update based on observed behavior
- Ignoring pressure-field coordination options for complex, multi-agent scheduling scenarios
For deeper implementation guidance, review secure P2P networking and secure AI networking best practices to harden your verification pipeline end to end.
A fresh perspective: Why most AI agent discovery processes fail (and how to succeed)
Most discovery failures are not caused by missing technology. They come from teams treating verification as an optional optimization rather than a core requirement. The teams we see struggle most are those who build fast, skip the trust layer to ship sooner, and then spend months untangling security incidents and intermittent failures they cannot reproduce.
Benchmark-driven methods consistently outperform intuition-based designs. If you are not running simulation-based stress tests against your discovery and verification stack before deployment, you are guessing. The 50% Sybil robustness result is not a theoretical ceiling. It is a real signal about how quickly unverified networks degrade when they encounter adversarial conditions.
Teams that iterate rapidly on both coordination strategy and trust verification outpace those who treat these as set-and-forget configurations. AI networking challenges in decentralized systems reward teams that treat discovery and trust as evolving systems, not one-time decisions.
Pro Tip: Build simulation-based stress tests that inject synthetic Sybil agents at increasing ratios. Run these before every major deployment. The goal is to find your network’s breaking point in a lab environment, not in production.
Power your peer-to-peer agent discovery with Pilot Protocol
You now have a clear, step-by-step approach to agent discovery, capability announcement, semantic querying, and trust verification. The next step is putting it into practice on infrastructure built specifically for this kind of work.
Pilot Protocol provides the peer-to-peer foundation that makes secure, trust-enabled agent discovery practical at scale. With built-in NAT traversal, encrypted tunnels, persistent virtual addresses, and mutual trust establishment, it removes the infrastructure complexity so you can focus on your agents. Explore robust peer-to-peer for AI agents to see reference implementations, ecosystem guides, and toolkits designed for exactly the kind of deployments this article covers. Start building with confidence today.
Frequently asked questions
What are the main phases of the AI agent discovery process?
Agent discovery operates in two phases: agents first announce their capabilities via structured metadata, then consumers query the network using semantic matching to locate and connect with relevant agents.
Why is decentralized discovery more resilient than centralized?
Decentralized DHT/gossip discovery scales and recovers far better than centralized registries, which are better suited to small or short-lived networks where simplicity outweighs resilience.
How can I improve trust and security during agent discovery?
Apply risk-aware verification using multi-factor checks including signed capabilities, trust scores, and interaction history. This approach keeps your network functional even when Sybil infiltration reaches 50%.
What role do taxonomies play in AI agent discovery?
OASF taxonomies standardize how agents describe their capabilities, making semantic queries accurate and enabling consistent discovery across different agent implementations and networks.
Does AI agent discovery require a central server?
No. Centralized registries work for small or short-lived deployments, but DHT and gossip-based discovery let agents announce and query each other directly, without a single point of failure. See decentralized P2P solutions for AI architectures for the tradeoffs.
Recommended
- Peer-to-peer networking examples every AI engineer should know
- Top AI agent network examples for secure, scalable connectivity
- Build an AI Agent Marketplace with Discovery & Reputation
- Why federated learning needs peer-to-peer communication, not gRPC
- Understanding autonomous agent networking for distributed AI
- AIOpportunities | OnTheRice
- How to Rank in AI Search | Proven SEO Strategies | Aim Set Win