Persistent network addressing for secure AI systems
Persistent network addressing for secure AI systems

TL;DR:
- Persistent network addressing provides stable, reliable peer-to-peer connections essential for AI agents.
- Most cloud environments favor ephemeral IPs, requiring complex solutions for persistent addressing at scale.
- Future AI networking favors topology-aware, semantic addresses with integrated security, moving beyond static IPs.
Many teams building distributed AI systems assume network addresses just work. They don’t. In Kubernetes and most cloud environments, pod IPs are ephemeral by design, meaning they change every time a workload restarts, scales, or migrates. For stateless web apps, that’s fine. For autonomous AI agents that need direct, trusted, peer-to-peer communication, it creates real connectivity and security gaps. This guide breaks down what persistent network addressing actually means, how it differs from ephemeral approaches, where popular cloud environments fall short, and what advanced methods exist to solve the problem at scale. If you’re building agent fleets or distributed automation, this is foundational knowledge.
Table of Contents
- Defining persistent network addressing
- Common approaches and alternatives in cloud environments
- Semantic and path-aware approaches for decentralized networks
- Risks, trade-offs, and best practices
- A fresh perspective: The future of persistent network addressing in AI ecosystems
- Enable secure, persistent networking for autonomous systems
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Persistent vs. ephemeral | Persistent addresses stay mapped to nodes for stable communication, while ephemeral addresses are temporary and change often. |
| Cloud limitations | Most cloud platforms require extra tools or configuration to support persistent network addressing for autonomous agents. |
| Advanced alternatives | Semantic addressing methods like PASA offer new ways to provide stable, direct connectivity for decentralized AI and IoT systems. |
| Management trade-offs | Adopting persistent addressing increases management effort and introduces risks like IP exhaustion. |
| Best practices matter | Follow specific guidelines to minimize security and reliability risks when implementing persistent network addressing. |
Defining persistent network addressing
A persistent network address is an address assigned to a node, agent, or service that remains stable across restarts, re-deployments, and infrastructure changes. It doesn’t shift when a pod reschedules. It doesn’t rotate on reconnect. The address is yours, and anything that knows it can reach you reliably over time.
Contrast that with ephemeral addressing, where addresses are assigned dynamically at runtime and released when the workload stops. Kubernetes follows this model by default. Every pod gets an IP from the cluster’s CIDR range, and that IP is recycled the moment the pod terminates. This is great for scalability and resource efficiency. It’s a problem for any system that depends on stable, long-term identity.
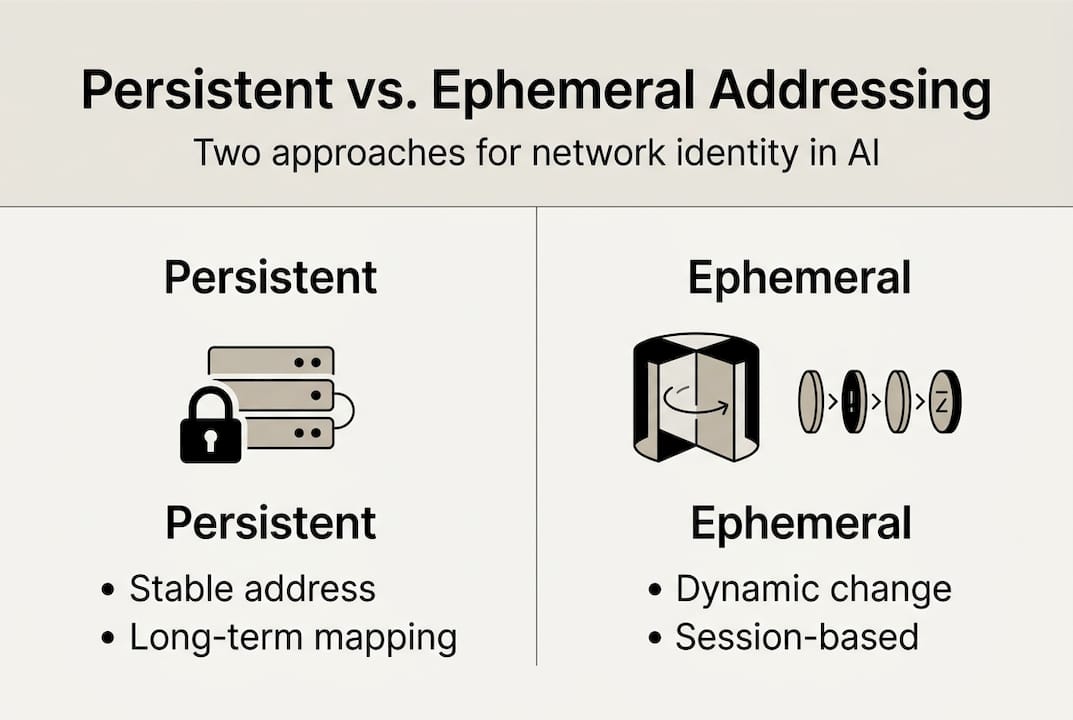
For AI agents, the distinction matters enormously. An agent that needs to receive tasks, stream data, or maintain a trust relationship with a peer can’t do that reliably if its address changes unpredictably. You’d need a service layer, a message broker, or a central coordinator to bridge the gap. Each of those introduces latency, a failure point, and an operational dependency.
Persistent addresses explained are especially relevant in decentralized environments where no central registry exists to resolve current addresses in real time.
Here’s a direct comparison:
| Feature | Persistent addressing | Ephemeral addressing |
|---|---|---|
| Address stability | Stable across restarts | Changes on restart or reschedule |
| P2P communication | Direct and reliable | Requires discovery layer |
| Management overhead | Higher | Lower |
| IP exhaustion risk | Elevated at scale | Lower |
| Security model | Identity-bound | Session-bound |
| Best fit | AI agents, IoT, P2P systems | Stateless web services |
The management trade-offs are real. IP address persistence enables stable peer-to-peer connections but increases management complexity and IP exhaustion risk. Some proposals like PRDO shift security responsibility to the provider level, which can reduce per-node overhead but introduces new trust assumptions.
“Persistent addressing gives your infrastructure a stable identity layer, but identity without lifecycle management becomes a liability. You need processes for address retirement, not just address assignment.”
The core principle: persistent addressing is a deliberate design choice, not a default. It requires intentional allocation, lifecycle planning, and integration with your security model from day one.
Common approaches and alternatives in cloud environments
Most cloud platforms weren’t built with persistent agent identity in mind. They were built for scalable, replaceable compute. That mismatch creates friction when you try to run stable, addressable AI workloads on top of them.
In Kubernetes, the default CNI (Container Network Interface) assigns pod IPs dynamically. AWS EKS and Azure AKS have no native persistent addressing for pods. Google GKE is similar. The assumption in all three is that services, not pods, are the stable identity layer. But services add indirection, and for direct agent-to-agent communication, indirection costs you control.
Here’s how teams typically work around this:
| Approach | Platform | Limitation |
|---|---|---|
| Elastic IPs | AWS | Node-level only, not pod-level |
| Fixed IPs | Azure | Manual allocation, limited scale |
| kube-vip | Any K8s | Adds HA complexity |
| Custom IPAM | Any K8s | High operational overhead |
| Static routes | Multi-cloud | Fragile across regions |
Common pitfalls when implementing these solutions:
- Address reuse conflicts: Recycled IPs can cause stale DNS or trust cache hits from prior workloads.
- Cross-region inconsistency: An IP that’s fixed in us-east-1 has no stable meaning in eu-west-1.
- Scaling bottlenecks: Static IP pools don’t scale as smoothly as dynamic allocation.
- Audit gaps: Persistent IPs that aren’t tracked create security blind spots over time.
For teams connecting agents across clouds, the challenge compounds. Each cloud has its own networking primitives, and stitching them together with static IPs or VPNs introduces latency and configuration complexity that grows fast.
Pro Tip: Don’t confuse MAC-layer protocols like CSMA/CD with IP-level persistent addressing. They operate at different layers of the stack. Conflating them leads to misdiagnosed routing issues and wasted debugging time. Focus your persistent addressing strategy entirely at Layer 3 and above.
If you’re evaluating multi-cloud networking strategies for distributed AI, understanding these limitations up front saves significant rework later. The right solution usually involves an overlay network rather than trying to force persistence into the underlying cloud fabric.
Semantic and path-aware approaches for decentralized networks
Default cloud solutions have a ceiling. Once you move beyond a single cluster or region, the limitations of static IP management become hard to ignore. That’s where newer, topology-aware approaches enter the picture.

Path-Aware Semantic Addressing (PASA) is one of the most promising. Defined in an IETF draft for IoT and LLNs, PASA embeds network topology directly into IPv6 addresses. This means a router can forward packets based on the address structure alone, with no routing protocol required. It’s stateless forwarding at the network layer.
For static or semi-static decentralized topologies, this is a significant win. No routing table updates. No protocol overhead. The address itself carries the path.
Ideal scenarios for semantic persistent addressing:
- IoT agent networks where devices have fixed physical positions and predictable communication paths.
- Edge computing clusters that operate in isolated environments with defined topologies.
- Low-power, lossy networks (LLNs) where routing protocol overhead is prohibitive.
- Air-gapped or offline-first systems that can’t rely on dynamic discovery.
- Static multi-agent pipelines where each agent has a defined role and consistent upstream or downstream peers.
For decentralized P2P AI networking, PASA-style addressing is appealing because it removes the need for a centralized address resolver. Each node’s address encodes its position in the network graph. Routing becomes a function of address parsing, not table lookups.
Pro Tip: GKE users can prioritize unified IPAM solutions that align with your overlay design before adopting semantic addressing. Also, avoid conflating MAC-layer behavior with IPv6 semantic schemes. They’re solving different problems at different layers. PASA applies at Layer 3 and targets topology-aware forwarding, not link-layer coordination.
For teams exploring decentralized communication protocols, PASA represents a direction where the address itself becomes an expression of network structure. That’s a shift from treating addresses as arbitrary identifiers to treating them as structured, meaningful, topology-aware tokens.
Risks, trade-offs, and best practices
Persistent addressing isn’t universally better. It’s contextually better. And if you apply it without the right management practices, it creates problems that are harder to fix than the ones it solves.
Persistent addressing increases management complexity and IP exhaustion risk in scalable environments. At small scale, this is manageable. At hundreds or thousands of agents, it requires real infrastructure.
Key risks to plan for:
- IP exhaustion: Fixed address pools run out. If your agent fleet scales faster than your IP allocation, workloads fail to start.
- State drift: An address assigned to a decommissioned agent that isn’t properly retired can cause conflicts or stale trust relationships.
- Security surface expansion: Stable addresses are easier targets. They’re predictable, which aids attackers and defenders equally.
- Operational overhead: Every persistent address needs lifecycle tracking, audit logging, and access control.
“Ephemeral addressing forces you to build systems that tolerate identity change. Persistent addressing lets you skip that, but only if your management discipline is tight. Most teams underestimate what that discipline actually requires.”
Best practices for implementation:
- Use address registries: Maintain a centralized or federated IPAM system that tracks every persistent address, its owner, and its expiration.
- Automate retirement: Build deallocation into your agent lifecycle. When an agent stops, its address should be released or held for a defined grace period.
- Apply least-privilege routing: Persistent addresses should only be reachable by authorized peers. Use firewall rules or overlay access control.
- Monitor for drift: Set alerts for address conflicts, unexpected traffic patterns, or stale entries in your registry.
- Test failure scenarios: Verify that your system handles address unavailability gracefully, especially in cross-region setups.
Review secure networking best practices alongside your addressing strategy. Also consider automation tips for AI networking to reduce manual overhead in address management.
For a broader view of what makes distributed systems hard, the decentralized networking challenges facing AI deployments extend well beyond addressing. But addressing is often where teams first feel the friction.
A fresh perspective: The future of persistent network addressing in AI ecosystems
Here’s the part most articles skip: persistent addressing is often misapplied because teams treat it as a configuration choice rather than an architectural one. They add static IPs to fix a connectivity problem without asking whether the system design actually requires persistence, or just consistency.
The real shift coming in AI networking isn’t more persistence. It’s smarter persistence. Federated IPAM, semantic addressing like PASA, and overlay networks with built-in identity are converging into a model where addresses carry meaning, not just location.
Most teams struggle because they inherit network assumptions from web-app thinking. Stateless, horizontally scaled, address-agnostic. That model breaks for agents that hold state, maintain trust relationships, and need direct communication paths.
The future looks like topology-aware, dynamically scoped addressing with cryptographic identity at the core. Not static IPs bolted onto cloud VPCs. If your agents need network independence from cloud dependency, the architecture needs to reflect that from the start. Challenge the legacy pattern. Design for the agent, not the server.
Enable secure, persistent networking for autonomous systems
If your AI systems need stable, direct communication across clouds, regions, or air-gapped environments, persistent addressing is a critical architectural requirement. The concepts in this guide give you the foundation. But implementation is where the real work happens.
Pilot Protocol provides network-layer infrastructure for autonomous agents built around persistent virtual addresses, encrypted tunnels, NAT traversal, and mutual trust. You don’t need to bolt static IPs onto cloud VPCs or manage custom IPAM to get stable agent identity. Visit pilotprotocol.network to explore how we handle persistent addressing, P2P connectivity, and cross-cloud agent networking so your team can focus on building, not maintaining infrastructure.
Frequently asked questions
What is the main advantage of persistent network addressing?
Persistent network addresses provide stable, direct communication paths between agents or nodes. This is essential for reliable peer-to-peer connections in decentralized environments where identity consistency matters.
How do persistent addresses differ from ephemeral addresses in Kubernetes?
Kubernetes assigns ephemeral pod IPs that change on each restart or reschedule, while persistent addresses stay static and support long-term peer connections, though they require greater management discipline.
Can I achieve persistent network addressing on major clouds like AWS or Azure?
Major clouds don’t natively support persistent pod-level addressing in Kubernetes. You need tools like Elastic IPs, kube-vip, or custom IPAM to achieve stable addresses at scale.
What is Path-Aware Semantic Addressing (PASA)?
PASA is a method that encodes topology into IPv6 addresses, enabling stateless packet forwarding ideal for decentralized, low-power, and IoT-centric network architectures.
Are there risks in using persistent network addresses?
Yes. Persistent addresses increase IP exhaustion risk and configuration drift if lifecycle management and address retirement are not properly automated and monitored.